Pescatore: A real time URL classification system for SOCs
Author: Roberto Sponchioni
Phishing is a form of identity theft in which cyber criminals build replicas of target websites in order to steal sensitive information such as username/password, credit card details and other sensitive information.
According to a recent report from Proofpoint, “The Human Factor 2017”, phishing attacks (social engineering via email) continue to be the most common attack vector, and one of the largest security challenges that individuals and companies are facing in order to keep information secure. Again, based on the Proofpoint report, on average 90% of malicious URL messages lead to credential phishing pages rather than to exploit kits, meaning that cyber criminals are now leveraging human interaction more than automated exploits to infect systems and steal confidential data.
As DocuSign became a more often used phishing lure, and our commitment to protecting our customers and our employees remained strong, we needed a reliable, fast and proactive way to fight against cyber criminals. For this reason, we internally developed a real-time automated URL classifier that can, within mere minutes, identify new phishing URLs with the aim to proactively protect our assets.
Pescatore in Pills
Our award-winning in-house system is named Pescatore, fisherman in Italian, and its aim is to automatically classify URLs within minutes.
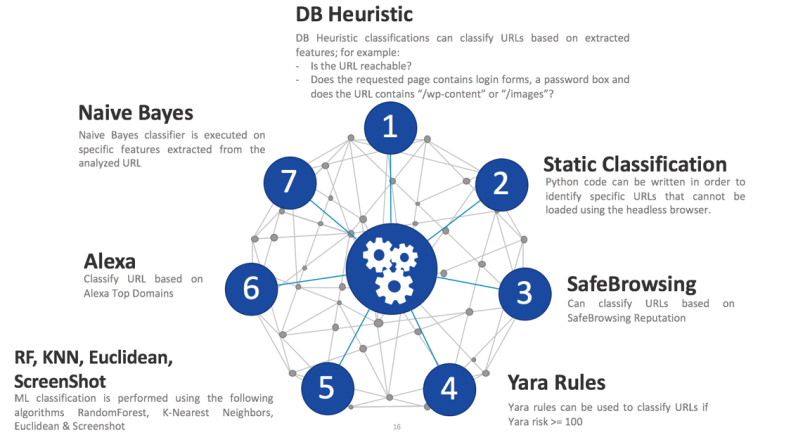
Pescatore is made up of different modules and each of them works separately and performs different tasks. Eventually, all the extracted data is used to classify URLs. Moreover, the system is scalable and it can be deployed all around the globe to speed up analysis time and to classify URLs that might not deliver any content if they are not being viewed from within specific countries.
Pescatore includes the following modules:
- Web Browser: capable of taking a screenshot of the page and extracting the page source code and features that are used in the Machine Learning module
- Static Classifier: classifies new URLs by using different methodologies:
- Algorithmic Classification: an algorithm is used to classify unusual pages that cannot be rendered properly by the headless browsers
- Yara Classification: a rule-based system that can classify newly analyzed URLs and/or provide insights into the phishing kit to the analysts (e.g.: targeted brands in the phishing page)
- DB Classification: a database based classification system that, based on the extracted features, can be used to classify URLs that are known to be phishing sites (e.g.: long URLs that contains multiple subdomains and specific keywords in the analyzed page)
- Machine Learning Classifier: automatically classifies URLs by using different algorithms, including Random Forest, Naïve Bayes, Euclidean distance and K-Nearest Neighbors
- SandBox submission: automatically submits any URL delivering executable files to our internal sandbox system and based on the result, classifies the URL accordingly (e.g.: Malicious or Benign)
- Screenshot correlator: analyzes the screenshot of each submitted URL, verifies if it is similar to known Phishing screenshots and can trigger a classification based on specific thresholds
- API: allows our internal systems to automatically submit new URLs and collect details regarding each analyzed URL
- UI: gives the analysts the ability to investigate specific phishing kits allowing them to speed up analysis time
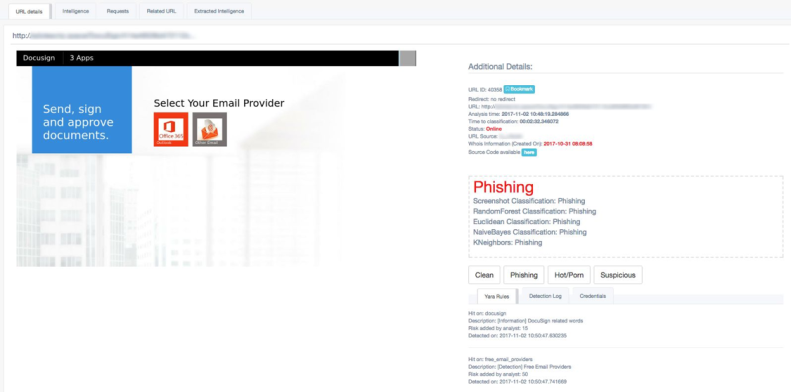
Classification Methods
Automated URL classification aims to identify newly created phishing domains. This can be done in different ways, for example by using static signatures on the content of the page, on the URL itself and on the Whois information. Unfortunately, this is a very weak approach as it does not take into consideration cases where, for example:
- A site has been hacked and the Whois information is irrelevant as the domain might have been created years ago,
- The phishing pages change quickly, and in order to stay one step ahead of the crooks, static classification methods are useless.
Pescatore uses different methodologies, and, by using all of them, the results are more reliable and also very efficient.
- Static and DB classification: based on different features which are normally seen in Phishing pages, for example, if the analyzed page is delivered over HTTP and contains a form, an input for a username, password and a CVV for a credit card and if the domain is newly created, the URL more than likely is going to be malicious and for this reason will be classified as phishing;
- Algorithmic classification: as the system is using a headless browser, some pages might not be fully loaded/rendered and hence the content might be truncated, but at the same time specific traits of the page may be visible, so with an ad-hoc parser and an algorithmic classification system, Pescatore can classify URLs based on their partial content;
- Reputation based classification: by using different reputation systems such as Alexa and Google SafeBrowsing, in conjunction with other classification methods, Pescatore can classify URLs as Clean or Phishing based on their reputation;
- Machine Learning classification: by using different algorithms, such as Random Forest, KNN, Euclidean Distance, Naïve Bayes and Screenshots correlation, the system can automatically predict with a very high confidence, as per table below, the typology of a URL (clean, phishing, etc.). Furthermore, in order to be more reliable and decrease the False Positive rates, a URL is classified by combining all the generated machine learning predictions and only if a threshold is reached.
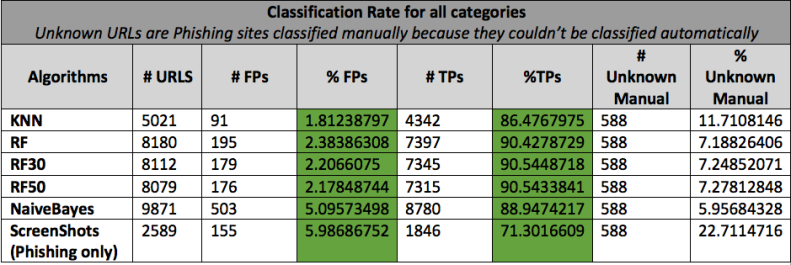
Pescatore in Figures
The following table shows the total number of URLs analyzed by each machine learning algorithm during 3 months of testing. Each machine learning algorithm has a very high True Positive rate, about 90% and a very low False Positive rate, about 2 to 5%, depending on the algorithm. The algorithms work pretty well on their own, however, to make the system less FP prone and more reliable, Pescatore uses a method called ensemble learning which combines multiple learning algorithms to obtain a better predictive performance. This means that the classification is triggered only if multiple algorithms predict a specific category and a certain threshold is reached.
Considering the prevalence and rapid evolution of phishing threats, automated detection is a non-trivial task. But, by implementing multiple technologies and algorithm such as those outlined here, we can improve the reliability of the classification and, therefore, the automatic detection of malicious URLs.
Industry Recognition
DocuSign’s in-house system, Pescatore, was just recognized as an honoree of the 2019 CSO50 Award from IDG's CSO. This prestigious honor is bestowed upon a select group of organizations that have demonstrated that their security projects or initiatives have created outstanding business value and thought leadership for their companies. DocuSign will formally be recognized for Pescatore at the CSO50 Conference + Awards being held in April 2019 at the Talking Stick Resort in Scottsdale, Arizona.
The CSO50 Awards were scored according to a uniform set of criteria by a panel of judges that includes security leaders and industry experts. To find out more about this recognition and the CSO50 Award, see here .